
The world of artificial intelligence is witnessing a new wave of innovation with the introduction of the ONE-PEACE AI model. Designed as a highly extensible, general-purpose representation model, ONE-PEACE marks a significant shift in handling multi-modal tasks, accommodating vision, audio, and language modalities with unmatched flexibility and scalability. In this blog, we explore the key features, architecture, and potential of the ONE-PEACE AI model, setting a new standard for future developments in AI.
Peng Wang, Shijie Wang, Junyang Lin, Shuai Bai, Xiaohuan Zhou, Jingren Zhou, Xinggang Wang, Chang Zhou
DAMO Academy, Alibaba Group Huazhong University of Science and Technology
Paper Source
CODE ON GitHub
The ONE-PEACE AI Model at a Glance
ONE-PEACE is a 4 billion-parameter model aimed at seamlessly aligning and integrating representations across multiple modalities—vision, audio, and language. Its architecture is designed to easily accommodate additional modalities, offering a platform for unlimited modal expansion. By harnessing scalable multi-modal tasks, ONE-PEACE achieves exceptional results on both uni-modal and multi-modal tasks without pre-trained model dependency.
ONE-PEACE Model Architecture
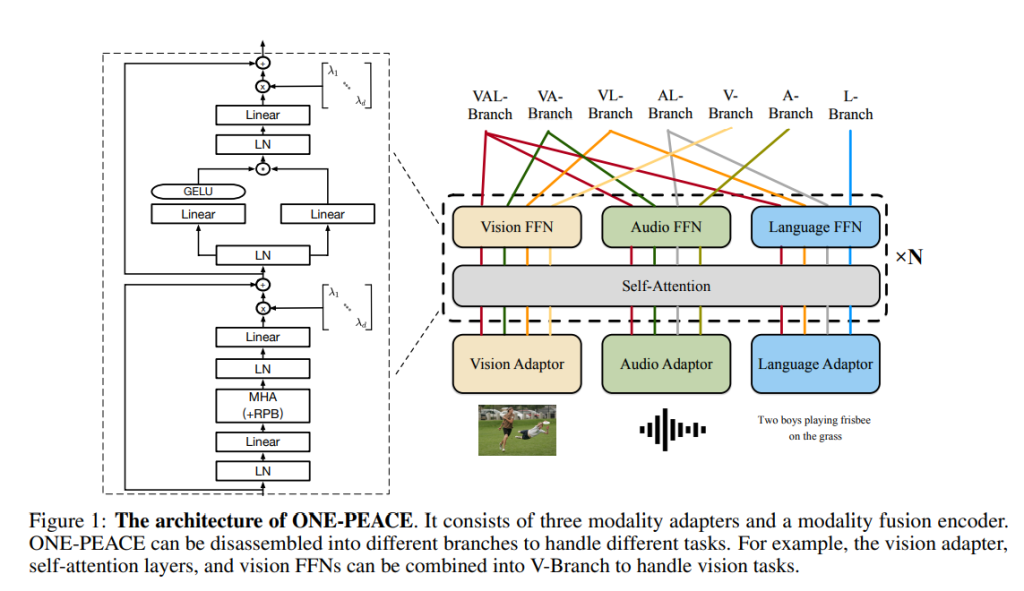
The architecture of ONE-PEACE is built to be modality-agnostic, consisting of three modality adapters and a modality fusion encoder. This framework supports a dynamic and efficient approach to integrating multiple data types through:
- Modality Adapters: These adapters allow ONE-PEACE to process vision, audio, and language data by converting raw signals into a unified representation. Each adapter can be customized, whether through transformers or other networks, to suit the specific needs of the modality.
- Modality Fusion Encoder: By employing a shared self-attention layer with specialized feed-forward networks (FFNs) for each modality, the fusion encoder facilitates seamless information exchange across modalities.
Core Pretraining Tasks
ONE-PEACE leverages cross-modal contrastive learning and intra-modal denoising contrastive learning as its primary pretraining tasks:
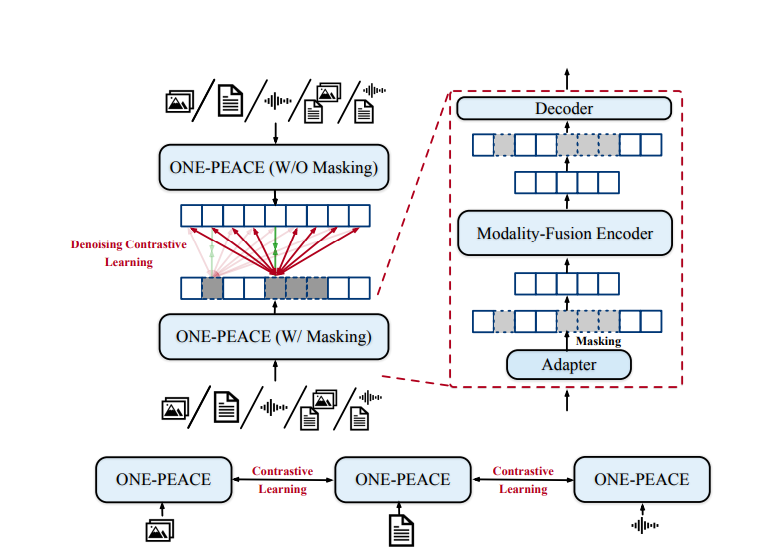
- Cross-Modal Contrastive Learning: This approach enhances the model’s ability to align semantic spaces across modalities, making it effective for tasks like image-audio or image-text retrieval.
The loss function is shown below:
- Intra-Modal Denoising Contrastive Learning: A unique feature of ONE-PEACE, this task preserves fine-grained details within each modality. By masking certain units (like image patches or audio tokens), the model learns robust representations, ensuring higher accuracy in both cross-modal and uni-modal tasks.
Performance Highlights
With its innovative design and scalable architecture, ONE-PEACE has achieved outstanding results across a wide array of benchmarks:
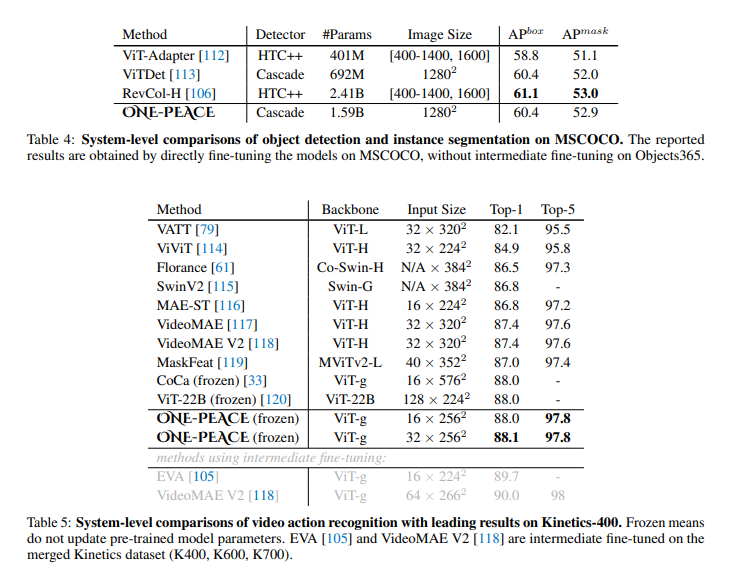
- Vision Tasks: Scoring 89.8% top-1 accuracy on ImageNet and excelling in semantic segmentation and object detection tasks, ONE-PEACE outperforms many existing models without relying on external pre-trained models.
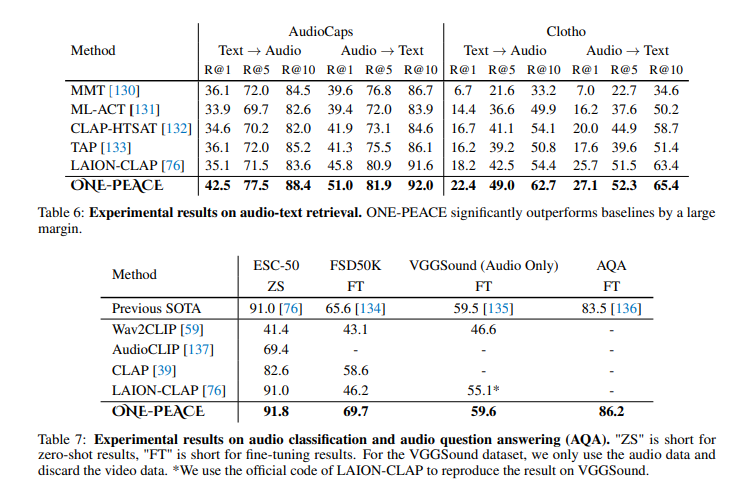
- Audio-Language Tasks: From audio classification to audio-text retrieval, ONE-PEACE outshines its competitors, achieving state-of-the-art scores in datasets like AudioCaps and ESC-50.
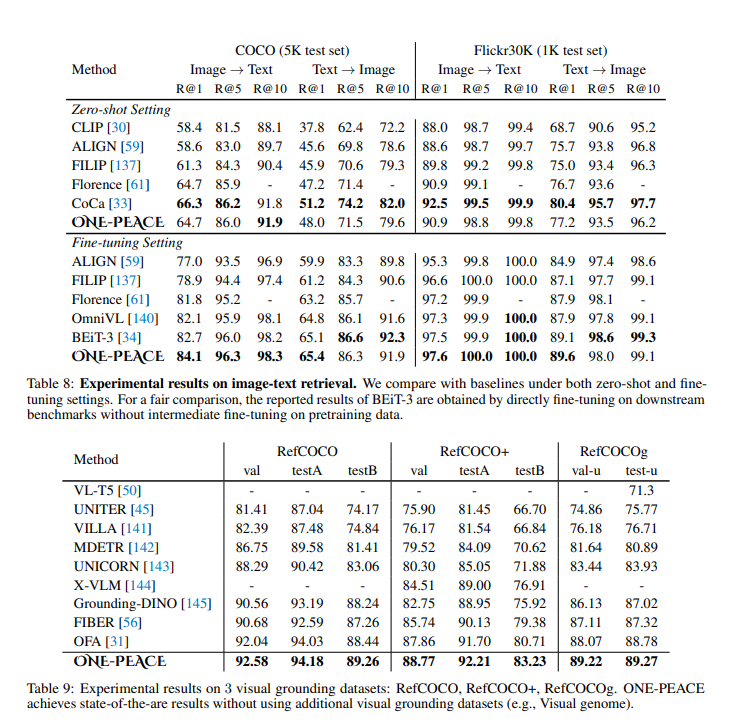
- Multi-Modal Fusion Tasks: In tasks that require image-text or audio-text retrieval, ONE-PEACE demonstrates superior alignment between different modalities, positioning it as a powerful tool for complex AI tasks in fields like visual grounding and video action recognition.
Future Directions for ONE-PEACE
The potential of ONE-PEACE extends far beyond its current capabilities. As it continues to evolve, future updates may introduce additional modalities like video, 3D point clouds, and potentially integrate with large language models (LLMs). By enabling a broader range of interactions, ONE-PEACE has the potential to set new benchmarks in multi-modal AI.
Conclusion
The ONE-PEACE AI model is a testament to the evolving landscape of artificial intelligence, addressing the growing need for a flexible, scalable, and highly integrative model. By offering a unified solution that bridges multiple modalities, ONE-PEACE stands as a pioneering approach toward unlimited modal expansion. Whether in vision, audio, language, or beyond, ONE-PEACE’s versatility makes it a critical advancement in the journey toward a more interconnected AI ecosystem.
For those keen on exploring the details of ONE-PEACE, the open-source code is available for further research and experimentation. The possibilities with this model are boundless, paving the way for innovative applications in fields such as healthcare, autonomous systems, and immersive virtual experiences.
By embracing a multi-modal future, ONE-PEACE represents the next evolution of AI—where the only limitation is the scope of our imagination.
Leave a Reply