
Table of Contents
Byte Latent Transformer: A Revolutionary Step or a Flawed Leap?
Meta has yet again pushed the boundaries of AI research with its introduction of the Byte Latent Transformer (BLT). This revolutionary architecture eliminates tokenization—a standard practice in NLP—and replaces it with a patch-based byte grouping method. The implications of this shift are profound, promising improved efficiency, scalability, and robustness.
In this blog, we’ll dissect the BLT paper, breaking it down for both experts and beginners, while maintaining an analytical perspective. Let’s explore what makes BLT a groundbreaking innovation, highlight its merits, and critically evaluate its limitations.
Tokenization: The Old Guard
For decades, NLP models have relied on tokenization, which breaks text into tokens (e.g., words or subwords) before processing. This method simplifies input but introduces biases and inefficiencies:
- Compression Heuristics: Tokenization applies fixed rules to group bytes, often disregarding the semantic and syntactic nuances.
- Domain Sensitivity: Token vocabularies work well in specific domains but fail to generalize.
- Multilingual Inequity: Token vocabularies often favour dominant languages, sidelining less-resourced ones.
- Noisy Input Fragility: Tokenized systems are highly sensitive to minor input changes, like typos.
While successful, tokenization hinders flexibility, particularly as models scale to billions of parameters.
Byte Latent Transformer (BLT)
BLT aims to replace tokens with dynamically sized patches of bytes. It comprises three key components:
- Local Encoder: Groups raw bytes into patches using entropy-based criteria.
- Latent Transformer: Processes these patches, allocating computational resources dynamically.
- Local Decoder: Reconstructs byte-level sequences from patch representations.
This design ensures efficient computation by reserving more processing power for complex patches while simplifying predictable ones.
Dynamic Patching: The Core Idea
Unlike tokenization, BLT’s patching dynamically adapts to the data’s complexity:
- Entropy-Based Grouping: Bytes are segmented based on their entropy. Higher entropy indicates more uncertainty, warranting a new patch.
- Adaptive Scaling: In predictable contexts, patches grow larger, reducing computational overhead.
This approach is reminiscent of Multi-Timescale Structures, a concept where processes operate at varying temporal resolutions depending on the complexity of the data. Just as multi-timescale models allocate resources based on task difficulty over time, BLT’s entropy-based patching dynamically allocates compute resources based on input complexity. For example, a patch covering predictable whitespace may use minimal computing, while highly complex sections like mathematical equations receive more attention.
If you’re curious about how Multi-Timescale Structures operate in broader contexts, check out our in-depth blog on Multi-Timescale Structures to see how this concept aligns with cutting-edge AI innovations like BLT.
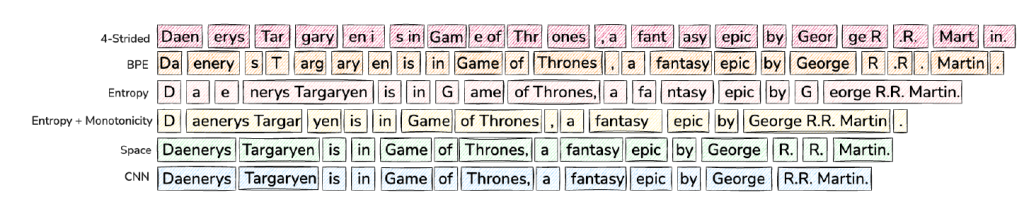
Let’s compare this approach with previous methods:
- Fixed Strided Patching: Simple but wasteful—uniform patch sizes ignore the content’s complexity.
- Space-Based Patching: A step forward, using spaces as natural boundaries, but it’s language-dependent and inflexible.
- BLT’s Entropy Patching: Dynamically adapts to complexity, ensuring optimal resource allocation.
Architecture Breakdown
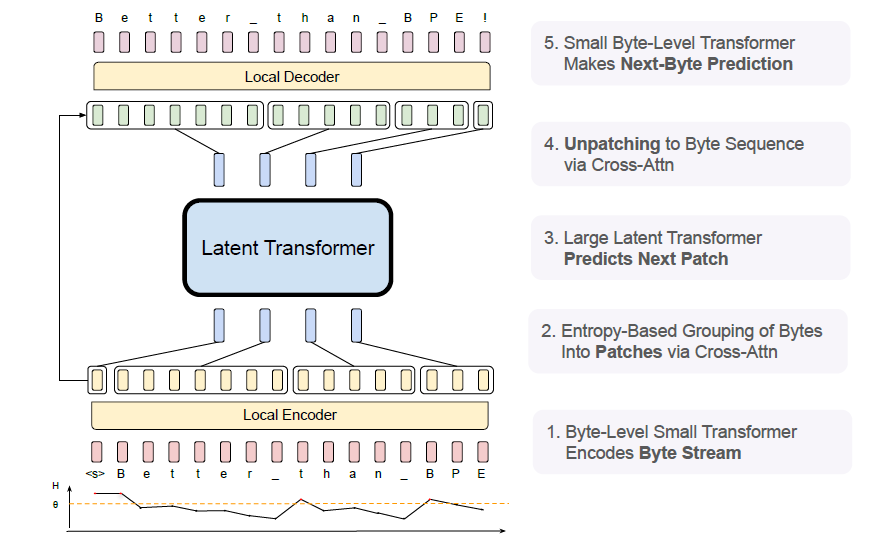
The BLT architecture utilizes:
- Local Encoder with Cross-Attention: Encodes bytes into patches, pooling representations dynamically.
- Latent Transformer: A large global transformer operating on patch representations, not individual bytes.
- Local Decoder with Reversed Cross-Attention: Converts patches back into byte sequences for generation tasks.
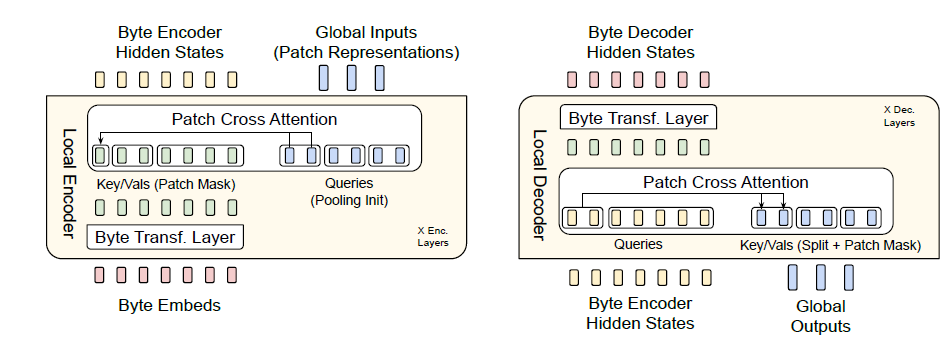
This diagram showcases the cross-attention mechanism at the encoder and decoder levels. The encoder aggregates byte-level details into patches, while the decoder reverses this process. This two-way interaction ensures the preservation of byte-level granularity, crucial for nuanced tasks like spelling correction or noisy input processing.
Strengths of BLT
1. Efficiency and Scalability
BLT introduces a new scaling axis: patch size. Larger patches reduce computational steps, freeing resources to scale the global model.
2. Robustness
BLT excels at tasks like noisy data handling (e.g., typos) and low-resource machine translation. Unlike tokenization-based models, it inherently understands byte-level details.
3. Flexibility
By bypassing fixed vocabularies, BLT supports diverse languages and modalities without retraining vocabularies.
Performance Benchmarks
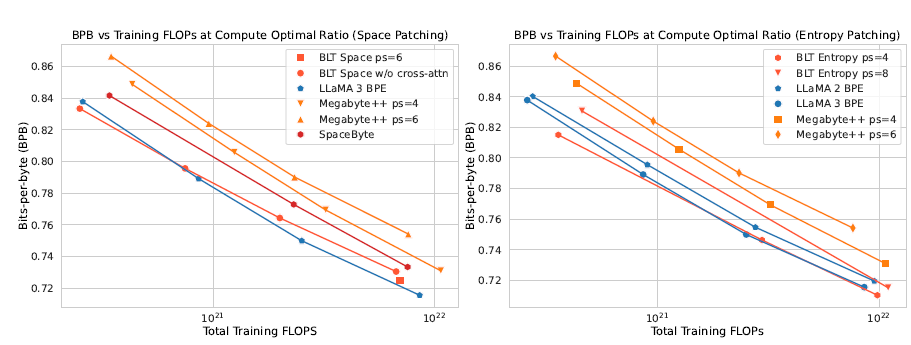
As illustrated in Figure 6, BLT matches or outperforms tokenized models like LLaMA 3:
- On large-scale tasks, BLT achieves comparable bits-per-byte (BPB) scores with fewer computational FLOPs.
- Dynamic patching (entropy-based) significantly outperforms static methods (space-based or fixed strides).
However, BLT requires careful tuning to balance patch size and computational efficiency. Larger patches save FLOPs but risk losing granular details.
Limitations and Criticisms
Training Complexity
One of the most significant hurdles with BLT is the additional overhead introduced by its dynamic patching mechanism. Unlike traditional tokenization, which uses a static vocabulary and straightforward preprocessing pipelines, BLT requires an entropy-based computation to determine patch boundaries. This preprocessing step is computationally expensive as it involves training and deploying a lightweight entropy model to predict the next-byte uncertainty. While this approach optimizes resource allocation during training and inference, it adds a layer of complexity that increases both time and computational costs.
Additionally, the interaction between patch size and entropy thresholds demands meticulous tuning. If patch sizes are too small, the computational gains from fewer transformer steps are lost, while overly large patches risk losing critical byte-level nuances. Such dependencies make the training pipeline harder to standardize and replicate across different datasets or use cases.
For organizations or researchers without Meta’s resources, integrating BLT into their workflows could be prohibitively complex. This is especially true for those accustomed to the relatively straightforward implementation of token-based systems.
Baseline Comparisons
While BLT offers several groundbreaking improvements, it does not entirely eclipse token-based models in all domains. For example, in tasks like code generation (as shown in the paper’s results), token-based systems such as LLaMA 3 perform better. This disparity likely stems from the tokenization process itself: programming languages benefit from predefined syntactic structures and a token vocabulary that compresses these structures effectively. BLT, on the other hand, processes raw bytes without any predefined knowledge of such structures, which can dilute its effectiveness for domain-specific tasks like coding.
Moreover, for short or predictable tasks where tokenization excels in compactly representing information, the dynamic patching of BLT might not provide a significant advantage. In these scenarios, the computational cost of entropy calculation and patch creation might outweigh its benefits. BLT’s dynamic flexibility, while a strength in general contexts, becomes less impactful when dealing with structured or low-entropy tasks.
This limitation suggests that while BLT challenges tokenization, it does not universally replace it. Certain domains will still benefit from traditional token-based systems, which raises questions about the need for a hybrid approach.
Accessibility
Accessibility remains a major challenge for BLT adoption. The complexity of its architecture—combining byte-level processing, entropy-based patching, and a latent transformer—places it out of reach for many smaller research teams or organizations without access to high-performance computing infrastructure. While Meta’s results are impressive, replicating such experiments at scale requires vast computational resources, expertise, and time.
The lack of pretrained models further exacerbates this issue. Token-based architectures like GPT and LLaMA have benefitted from an ecosystem of pretrained models and open-source tools, allowing even small teams to fine-tune and deploy state-of-the-art systems without starting from scratch. In contrast, BLT’s novelty means researchers currently have no such foundation, significantly raising the barrier to entry.
Meta has released code for BLT, but this alone is insufficient for democratizing its usage. To accelerate adoption, pretrained BLT models should be made publicly available, along with comprehensive documentation, tutorials, and benchmarks. This would enable researchers and developers to test BLT’s capabilities on their datasets without the heavy upfront investment of training from scratch.
Future Directions
BLT lays the groundwork for a tokenizer-free future. To improve:
- Hybrid Approaches: Combine tokenization for simple tasks and patching for complex scenarios.
- Broader Benchmarks: Evaluate BLT on a wider array of multimodal tasks.
- Open Access: Encourage adoption through open datasets and pre-trained weights.
Final Thoughts
Meta’s Byte Latent Transformer challenges the long-standing reliance on tokenization, paving the way for more flexible, efficient, and robust NLP systems. While not without flaws, BLT represents a pivotal step toward redefining how AI models interact with data.
For researchers and developers, BLT is both an inspiration and a challenge: to rethink established paradigms and embrace innovation. Let’s look forward to a future where models adapt seamlessly to the intricacies of human language.
Leave a Reply