
Table of Contents
Understanding where a person is looking—their gaze target—can unlock profound insights into human behaviour, intent, and interaction. From powering assistive technologies to enhancing human-computer interaction, gaze target estimation is a growing field. In this blog, we dive into Gaze-LLE (Gaze Target Estimation via Large-Scale Learned Encoders), a novel approach that simplifies gaze estimation while delivering state-of-the-art performance. Whether you’re an AI enthusiast or an advanced researcher, Gaze-LLE’s transformative methodology has something for everyone.
Paper is written by :
- Fiona Ryan (fkryan@gatech.edu)
- Ajay Bati (abati7@gatech.edu)
- Sangmin Lee (sangminl@illinois.edu)
- Daniel Bolya (dbolya@gatech.edu)
- Judy Hoffman (judy@gatech.edu)
- James M. Rehg (jrehg@illinois.edu)
- Georgia Institute of Technology, University of Illinois Urbana-Champaign
What is Gaze-LLE?
Gaze-LLE addresses the challenge of gaze target estimation, which involves predicting where a person is looking within a scene. This task requires understanding both the individual’s appearance and the contextual elements of the scene. Traditional approaches often rely on intricate, handcrafted pipelines that merge features from various encoders for scenes, heads, and auxiliary cues like depth and pose. Motivated by breakthroughs in general-purpose feature extraction for visual tasks, Gaze-LLE introduces a streamlined transformer-based framework. The core innovations of Gaze-LLE include:
- Simplified Architecture: Unlike traditional multi-branch designs requiring separate encoders and auxiliary models for cues like depth, pose, or scene features, Gaze-LLE consolidates these functionalities into a unified pipeline. This streamlining minimizes training requirements, accelerates convergence, and makes the model more adaptable to diverse datasets and tasks.
- Unified Feature Representation: At the core of Gaze-LLE is its ability to harness a frozen DINOv2 encoder to derive a singular, robust feature representation for the entire scene. This eliminates the need for multiple encoders, simplifying the process significantly while maintaining high accuracy and consistency across various environments.
- Positional Prompting: The framework introduces an innovative positional prompting technique. Integrating a lightweight module that processes person-specific positional prompts ensures that the gaze targets are decoded with precision, even in multi-person scenarios. This approach significantly reduces the computational burden without compromising on performance.
Why Does Gaze-LLE Matter?
- Efficiency: The model is lightweight, with only ~5% of the trainable parameters compared to traditional methods.
- Performance: Gaze-LLE achieves state-of-the-art results across major gaze estimation benchmarks.
- Generalization: Its reliance on robust foundation models allows for cross-dataset application without fine-tuning.
These advancements make Gaze-LLE a game-changer for applications in robotics, social behavior analysis, and more.
Key Innovations in Gaze-LLE
1. Leveraging Foundation Models
Gaze-LLE utilizes DINOv2, a cutting-edge transformer-based foundation model celebrated for its exceptional visual feature extraction capabilities. By freezing the DINOv2 backbone, Gaze-LLE achieves several advantages: it reduces computational overhead, accelerates training convergence, and ensures that the foundational features remain consistent and robust across various datasets and applications. This approach eliminates the need for extensive fine-tuning, making it a versatile tool for both research and deployment scenarios.
2. Positional Prompting
Gaze-LLE redefines gaze target estimation with its novel positional prompting mechanism. Traditional methods often rely on separate head branches and additional encoders, increasing complexity. Instead, Gaze-LLE introduces a lightweight module that integrates person-specific positional data directly into the decoder. By representing a person’s head position as a binary mask, this mechanism ensures precise gaze decoding without requiring additional training for head-specific encoders. This innovation enables Gaze-LLE to maintain accuracy even in challenging, multi-person environments.
3. Transformer Decoder
The heart of Gaze-LLE’s architecture is its advanced transformer decoder, which leverages global scene information to refine gaze predictions. Utilizing self-attention layers, the decoder effectively captures relationships across the entire scene, enabling accurate gaze estimation even in crowded or visually complex scenarios. The decoder’s design ensures scalability, making it suitable for both single and multi-person gaze estimation tasks while maintaining high computational efficiency.
How Gaze-LLE Works
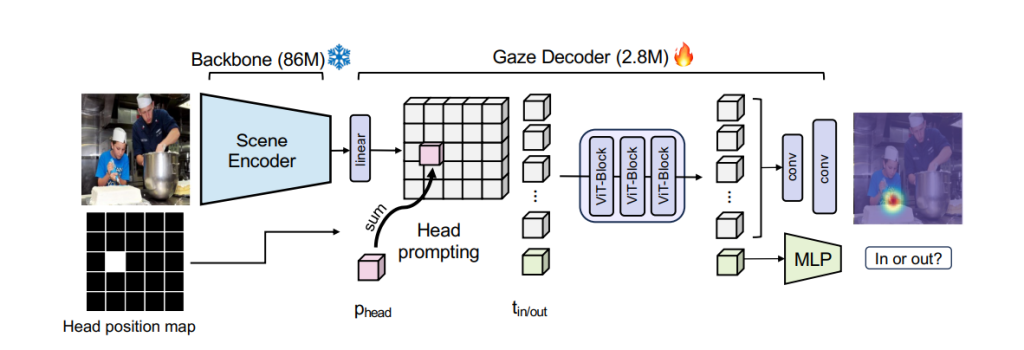
- Input Preparation: The process begins with providing an RGB image of the scene along with the bounding box coordinates that indicate the position of the person’s head. This initial step ensures that the system has both the visual context and the specific individual’s head location to focus on.
- Feature Extraction: Using the DINOv2 encoder, Gaze-LLE extracts a detailed feature map of the entire scene. This map captures essential visual details, including objects, spatial relationships, and context, which are crucial for accurate gaze estimation. The frozen nature of the DINOv2 encoder ensures that this step is both efficient and consistent across different inputs.
- Positional Prompting: To hone in on the specific person’s gaze, a learned embedding is applied to the feature map. This embedding incorporates the head position provided in the bounding box and adapts the feature map to prioritize gaze-relevant areas. By doing so, the model effectively highlights the key elements required for decoding the gaze target.
- Prediction: Finally, the lightweight transformer decoder processes the adapted feature map. It outputs a heatmap indicating the most probable gaze target within the scene, as well as a binary classification to determine whether the gaze target is inside or outside the visible frame. This dual prediction mechanism ensures both precision and contextual awareness in gaze estimation.
Benchmarks and Performance
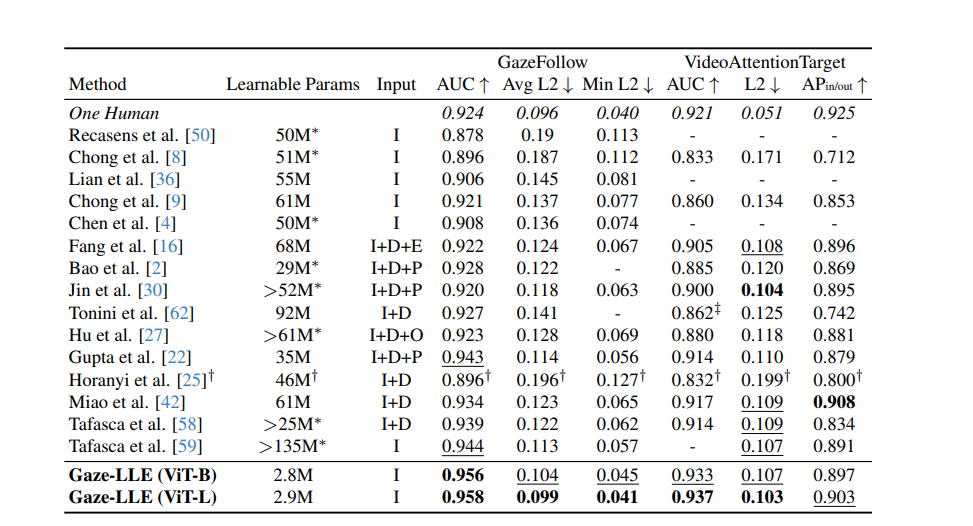
Gaze-LLE has been tested across prominent datasets like GazeFollow and VideoAttentionTarget. It consistently outperforms traditional methods in metrics such as:
- AUC (Area Under the Curve)
- L2 Distance
For example, on the GazeFollow dataset, Gaze-LLE achieves an AUC of 0.956 with only 2.8M learnable parameters—a fraction of what other methods require.
Comparison to State-of-the-Art
In extensive benchmarks on GazeFollow and VideoAttentionTarget, Gaze-LLE outperforms traditional approaches while requiring significantly fewer parameters. On VideoAttentionTarget’s in/out of frame prediction task, Gaze-LLE produces second-best results, but it achieves top performance across combined metrics.
The key results include:
- GazeFollow Dataset: Gaze-LLE achieves an AUC of 0.956 (ViT-B) and 0.958 (ViT-L), outperforming models that use more complex architectures with higher learnable parameters.
- VideoAttentionTarget (VAT): Gaze-LLE (ViT-L) achieves an AUC of 0.937 with an L2 error of 0.103, delivering strong results across metrics.
- Cross-Dataset Results: Gaze-LLE demonstrates excellent generalization without fine-tuning, surpassing methods on GOO-Real and ChildPlay datasets, even with domain gaps.
Furthermore, the lightweight architecture allows Gaze-LLE to converge much faster during training, achieving state-of-the-art results in less than 1.5 hours on an RTX 4090 GPU—a remarkable improvement over traditional approaches.
Applications of Gaze-LLE
1. Human-Computer Interaction
From virtual reality to gaming, understanding user gaze enhances immersion and control.
2. Assistive Technologies
Gaze tracking can empower individuals with disabilities, enabling communication and interaction.
3. Social Behavior Analysis
Analyzing gaze patterns can reveal insights into social interactions and group dynamics.
4. Retail and Marketing
Conclusion
Gaze analysis helps businesses understand consumer behaviour and optimize product placement.
Gaze-LLE represents a significant leap forward in gaze target estimation. Harnessing the power of foundation models like DINOv2 simplifies complex architectures while achieving exceptional performance. Whether you’re exploring gaze estimation for research or real-world applications, Gaze-LLE offers a robust and efficient solution.
Follow our blog to stay updated with the latest advancements in AI. For more in-depth insights, check out the official Gaze-LLE code repository.
Leave a Reply