In the ever-evolving world of technology, artificial intelligence (AI) and machine learning are revolutionizing the way we approach data analysis and prediction. One of the most intriguing applications of these technologies lies in the prediction of health insurance costs. This blog dives into a fascinating case study that utilizes Python, TensorFlow, and Scikit-learn to forecast health insurance charges based on personal attributes such as age, BMI, and smoking status.
This is a deep coding blog if you want to go for more light weight reading hear is a blog for you Securing Borders with Robotic Concepts, Infrared Detection, and AI
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
from sklearn.model_selection import train_test_split
import tensorflow as tf
import pandas as pdThe Power of Data
The journey begins with a dataset from the Machine Learning with R datasets repository. This particular dataset encompasses various factors that could potentially influence insurance costs, such as age, sex, BMI (body mass index), children, smoker status, and region. By analysing these variables, we aim to predict the charges a person might incur for their health insurance.
data = pd.read_csv("https://raw.githubusercontent.com/stedy/Machine-Learning-with-R-datasets/master/insurance.csv")Preprocessing: A Crucial Step
Before diving into the prediction model, it’s essential to preprocess the data. This process involves scaling numerical data and encoding categorical data to ensure our model can understand and learn from it. We use MinMaxScaler to normalize the age, BMI, and children features, and OneHotEncoder for categorical features like sex, smoker status, and region. This preprocessing step is crucial for improving model performance and ensuring accurate predictions.
ct = make_column_transformer(
(MinMaxScaler(), ["age","bmi", "children"]),
(OneHotEncoder(handle_unknown="ignore"), ["sex", "smoker", "region"])
)
X = data.drop("charges", axis=1)
y = data["charges"]Splitting the Health Insurance Data
To evaluate the model’s performance accurately, we divide the dataset into training and testing sets, with 80% of the data used for training and the remaining 20% for testing. This split helps in training the model on a substantial portion of the dataset while reserving a part for evaluation, ensuring that our model learns effectively and generalizes well to new data.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
ct.fit(X_train)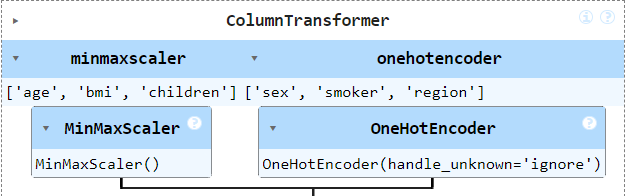
X_train_normal = ct.transform(X_train)
X_test_normal = ct.transform(X_test)X_train
X_train_normal
X_train_normal.shape
Building the Neural Network
The core of our prediction model is a neural network built using TensorFlow. This network comprises three layers: two dense layers with 100 and 10 neurons, respectively, and an output layer with a single neuron, since we aim to predict a continuous value (the insurance charges). We use Mean Absolute Error (MAE) as our loss function and the Adam optimizer to minimize this loss, focusing on improving the accuracy of our predictions.
learn more about Adam optimizer hear
tf.random.set_seed(42)
model = tf.keras.Sequential([
tf.keras.layers.Dense(100),
tf.keras.layers.Dense(10),
tf.keras.layers.Dense(1),
])
model.compile(
loss = tf.keras.losses.MAE,
optimizer= tf.keras.optimizers.Adam(),
metrics =["MAE"]
)Training and Evaluation of Health Insurance AI
Upon training the model with 200 epochs, we observe the learning process through the changes in loss, witnessing the model’s improving ability to predict health insurance costs accurately. Evaluating the model on the test set, we further assess its performance, ensuring that it can make reliable predictions on data it hasn’t seen during training.
history = model.fit(X_train_normal, y_train, epochs=200)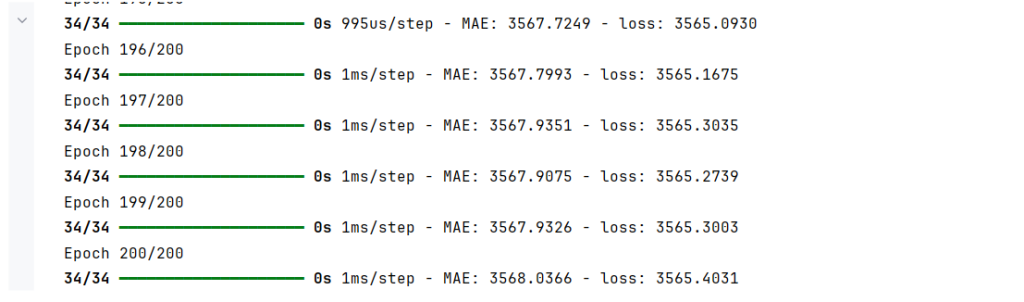
model.evaluate(X_test_normal, y_test)
Visual Insights
Lastly, a graphical representation of the training history showcases the model’s learning curve. This visualization is not only insightful for understanding the model’s performance over time but also highlights the importance of visual data exploration in machine learning projects.
pd.DataFrame(history.history).plot()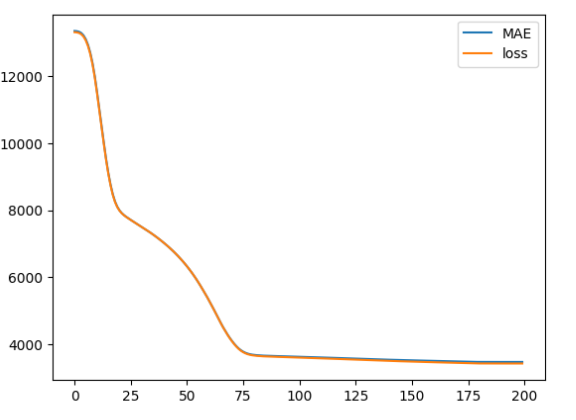
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
from sklearn.model_selection import train_test_split
import tensorflow as tf
import pandas as pd
data = pd.read_csv("https://raw.githubusercontent.com/stedy/Machine-Learning-with-R-datasets/master/insurance.csv")
ct = make_column_transformer(
(MinMaxScaler(), ["age","bmi", "children"]),
(OneHotEncoder(handle_unknown="ignore"), ["sex", "smoker", "region"])
)
X = data.drop("charges", axis=1)
y = data["charges"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
ct.fit(X_train)
X_train_normal = ct.transform(X_train)
X_test_normal = ct.transform(X_test)
X_train
X_train_normal
X_train_normal.shape
tf.random.set_seed(42)
model = tf.keras.Sequential([
tf.keras.layers.Dense(100),
tf.keras.layers.Dense(10),
tf.keras.layers.Dense(1),
])
model.compile(
loss = tf.keras.losses.MAE,
optimizer= tf.keras.optimizers.Adam(),
metrics =["MAE"]
)
history = model.fit(X_train_normal, y_train, epochs=200)
model.evaluate(X_test_normal, y_test)
pd.DataFrame(history.history).plot()
Leave a Reply